Chapter 2 Introduction
2.1 Assumptions
It is assumed that the reader is familiar with the basic concepts and motivations around using DataSHIELD for federated analysis. More information about this can be found here.
An understanding of DSLite will be useful in the sections that describe the use of synthetic data for developing analysis code.
Likewise, some knowledge of MagmaScript (which is basically JavaScript) would be helpful for the parts on harmonisation.
2.2 Motivation
DataSHIELD provides a platform to allow users to analyse remote, federated data sets by taking the analysis to the data. The benefits of this non-disclosive (i.e. not revealing fine-grained sensitive information) federated approach are that data can be harmonised and analysed without giving complete access to the data or transferring the data to another location. The avoidance of data transfer agreements is realised in DataSHIELD by only allowing analysts to execute commands that return non-disclosive summary statistics. A less desirable consequence of this approach is that it is more challenging for analysts to write, test and debug their scripts, and for data experts to harmonise data to common standards, when the data are not tangibly in front of them. One could say that it is like trying to build a Lego model while wearing a blindfold.
Writing, testing and debugging analysis code in DataSHIELD can be challenging because the analyst cannot easily see what is happening to the data they are manipulating. DataSHIELD relies on them only having summary access to the data. It is therefore possible for analysts to make checks to validate that their analysis is progressing as planned. This has to be done via non-disclosive information about the data that the analysis has generated. For example, to confirm that a subset into male and female groups has been successful, the analyst could ask for a summary of the original gender column and check the counts of male and female participants match the length of the subset dataframes. However, this process can be clumsy, especially for more complex functions such as ds.lexis and ds.reshape. More challenging can be when a command returns an error message - without seeing the data it can be hard to work out why things are not working.
With harmonisation, one option is to transfer and centralise the data, but this negates one of the benefits of the federated approach. While it is only necessary for the harmonisation team to receive the data, a lot of bureaucracy is required because a full data transfer is still needed. Another approach is to have each group harmonise their own data. The challenge with this approach is that there can be inconsistencies in the approach of different teams, and each team needs training and expertise in the harmonisation process. The approach that avoids this is for one expert group to perform the harmonisation for each dataset while it remains on its host’s server, and only allowing access to data summaries. The challenge again is that not being able to see the complete dataset makes it harder to write the harmonisation code.
2.3 Hypothesis for using synthetic data
R packages like synthpop (Nowok, Raab, and Dibben 2016) have been developed to generate realistic synthetic data that designed to be non-disclosive from an original, sensitive dataset. A DataSHIELD package built on synthpop functionality could be used to generate a synthetic data set on the server side which is then transferred to the client side. Users can then develop code on the client side while working with full access to synthetic data to confirm that it is working as expected. When the user is happy that the code is working correctly, it can then be applied to the real data on the server side. The user therefore has the benefit of being able to see the data they are working with, but without the need to go through labourious data transfer processes.
Other R packages that provide synthetic data generation are simstudy (Goldfeld and Wujciak-Jens 2020) and gcipdr. imstudy requires the user to define the characteristics of variables and their relationships. However, non-disclosive access via DataSHIELD can help provide these summary statistics such as means, variances and correlations. There is also the benefit that the user then has precise control over the nature of the synthetic data generated, and the data custodian knows that only summary statistics have been extracted. Likewise, gcipdr makes it easy for users to extract features such as mean, standard deviation and correlations via DataSHIELD, and use these to provide a more automated generation of the synthetic data. In dsSynthetic we provide functionality built on simstudy as it is more mature, has less complex dependencies and is faster. The compromise is that gcipdr should provide more accurate results, as it was designed to provide synthetic data that would allow actual inferences to be drawn as from the real data. However for our purposes we only want synthetic data that is realistic enough to develop analysis code and write harmonisation code: this work is then applied to the real data to get the inferences.
2.4 Overview of steps
The data custodian uploads the raw data to the server side and installs the server side package dsSynthetic, with the user installing the package dsSyntheticClient on the client side. The overall process of generating synthetic data for code development can be described by the following steps:
- The user calls functions in the
dsSyntheticClientpackage to request a synthetic copy of the real data - The synthetic but non-disclosive data set is made available on the client side.
- With the synthetic data on the client side, the user can view the data and develop their code. They will be able to see the how the data changes as the code is run.
- When the code is complete, it can be run on the server using the real data.
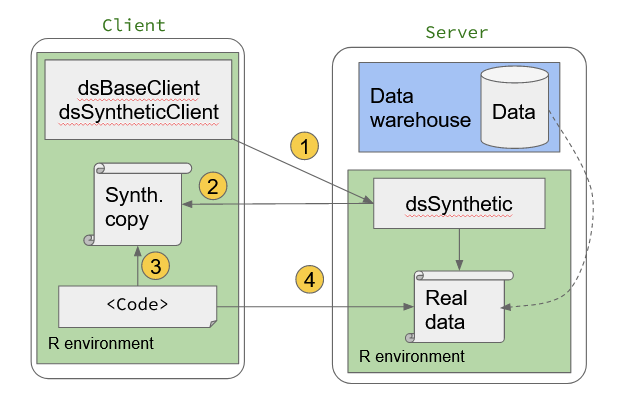
Figure 2.1: Generating synthetic data for developing code
2.5 Working with single studies
Some functions in the dsSynthetic packages are currently written to work with single studies. This means that these functions expect to receive a single connection object only, or they will throw an error. If you wish to use an existing connection object with connections to multiple servers, you can select a single connection like this:
The functions that require single connections are those involved in building the synthetic data on the client side, which can be a computationally intensive exercise. Therefore it is sensible to only do this for one study at a time. Also, in the case of harmonisation, the variables present will be different in different studies and as such will cause problems for many standard DataSHIELD functions (which typically require the same variables in all studies).
2.6 Prerequisites
To run the code examples in this book and use dsSynthetic in your own work you will need a working version of R with the appropriate DataSHIELD packages installed.
Using DataSHIELD on the client side requires the following R packages to be installed:
install.packages("DSOpal", dependencies = TRUE)
install.packages("dsBaseClient", repos = c("https://cloud.r-project.org", "https://cran.obiba.org"), dependencies = TRUE)To use dsSynthetic on the client side, the client package needs to be installed:
devtools::install_github("tombisho/dsSyntheticClient", dependencies = TRUE)
install.packages("simstudy")For chapter 4 we require DSLite, dsBase and dsSynthetic to be installed. This allows us to simulate the server side environment on the client side:
install.packages("DSLite", dependencies = TRUE)
install.packages("dsBase", repos = c("https://cloud.r-project.org", "https://cran.obiba.org"), dependencies = TRUE)
devtools::install_github("tombisho/dsSyntheticClient", dependencies = TRUE, ref = "main")For chapter 5 we need to install the R V8 package to simulate JavaScript in R. First some system level packages may need to be installed: On Debian / Ubuntu install either libv8-dev or libnode-dev, on Fedora use v8-devel.
References
Goldfeld, Keith, and Jacob Wujciak-Jens. 2020. Simstudy: Illuminating Research Methods Through Data Generation. Journal of Open Source Software. Vol. 5. 54. The Open Journal. https://doi.org/10.21105/joss.02763.
Nowok, Beata, Gillian M. Raab, and Chris Dibben. 2016. Synthpop: Bespoke Creation of Synthetic Data in R. Journal of Statistical Software. Vol. 74. 11. https://doi.org/10.18637/jss.v074.i11.